


Algorithmic Trading in Crypto
An Introduction by Galois Capital

An Introduction by Galois Capital
This article was originally written by Kevin Zhou at Galois Capital (Twitter) on their blog, and was re-published here with his permission.
In this article we explore the design and implementation of trading algorithms in the crypto space. In particular, we focus on execution algos, market making algos, and several market microstructure considerations. We also investigate where practice diverges from theory, especially in handling the idiosyncrasies of the crypto markets.
Execution Algos
The objective of an execution algo is to transition a portfolio state into a different one while minimizing the costs of doing so. For example, if you wanted to increase your BTCUSD exposure by 1000, you might not want to instantly slam a market order into the BitMEX book, incurring a significant amount of slippage. Instead you might consider slowly getting into the desired position over time with a combination of market and limit orders over a number of different exchanges.
An execution algo usually has 3 layers: the macrotrader, the microtrader, and the smart router.
The macrotrader layer breaks up a large meta-order or parent order into smaller child orders spread across time. This is effectively the scheduling piece of the entire algo. VWAP, TWAP, and POV are common and simple examples of macrotrader algorithms. Generally there are many different market impact models that can be used in designing a sophisticated macrotrader layer. Market impact models look at how the market reacts to an execution. Does the market stay where it is after an execution? Or does it move further away? Or does it come back to some degree? The two most seminal market impact models are the Almgren-Chriss (1999, 2000)permanent market impact model and the Obizhaeva-Wang (2013) transient market impact model. Given that, in practice, market impact is not permanent, Obizhaeva-Wang seems to coincide with reality better. Since then, many new models have been formulated to deal with its deficiencies.

market impact decay after trade execution
The microtrader layer decides for each child order, whether to execute it as a market order or a limit order and, if as a limit order, what price should be specified. Much less literature exists on microtrader design. This is because the size of a child order is usually such a small part of the entire market that it doesn’t really matter how you execute it. However, crypto is different since liquidity is very thin and slippage is significant even for commonly-sized child orders in practice. Microtrader design generally focuses on order arrival distributions against time and depth, queue position, and other features of market microstructure. Market orders (and crossing limit orders if we ignore latency) guarantee execution while resting limit orders have no such guarantees. If execution is not guaranteed, you risk falling behind on the schedule set by the macrotrader.
The smart router layer decides how to route executions to different exchanges/venues. For example, if Kraken has 60% of the liquidity and GDAX (Coinbase Pro/Prime) has 40% of the liquidity up to a given price level, then any market order decided upon by the microtrader should be routed 60–40 to Kraken-GDAX. Now you could make the argument that arbitragers and market makers in the market will transport liquidity from one exchange to another so if you execute half your order on Kraken and wait a few seconds, some of that liquidity would replenish from arbers and stat arbers moving over GDAX liquidity to Kraken and you would be able to get the rest done at a similar price. However, even in that case the arber would charge you something extra for their own profit as well as pass on their own hedging costs like Kraken’s maker fee. Moreover, some market participants post more than the size they want done across multiple venues and race to cancel excess size once they are hit. Ultimately, it’s best to have your own native smart routing. Native smart routing also has a latency advantage against third party smart routing services. In the former case, you can route directly to exchanges while in the latter case, you first need to send a message to the third party service and then they will route your order to exchanges (plus you have to pay the third party a routing fee). The sum of any two legs of a triangle is greater than the third leg.
Market Making Algos
Market making is about providing immediate liquidity to other participants in and being compensated for it. You take on inventory risk in return for positive expected value. Ultimately, the market maker is compensated for two reasons. First, the market takers have high time preference and want immediacy. Market makers who facilitate liquidity to takers are, in turn, compensated for their lower time preference and patience. Second, the market maker PnL profile is left-skewed and generally most people have right-skew preference. In other words, market makers are analogous to bookies in betting markets, casinos, insurance companies, and state lotteries. They win small frequently and lose big infrequently. In return for taking on this undesirable return profile, market makers are compensated with expected value.

At a high level, limit orders are free options written to the rest of the market. The rest of the market has the right but not the obligation to buy or sell an asset at the limit price of a limit order. In a perfectly informed market, no one would sell free options. It is only because the market is, in aggregate, not perfectly informed that it would never make sense to sell free options. On the flip side, if the market was perfectly uninformed, a risk-neutral market maker would be willing to sell these free limit order options at even an infinitesimal spread since all trading is noise. Obviously, real markets have a blend of participants, each with a unique level of informedness.
In designing a market making algo, there are three perspectives to consider: the market maker’s, the market takers’, and other market makers’.
The market maker’s own perspective is represented by their inventory. If you already have too much asset exposure, you will probably lean/skew your quotes down and vice versa for having too little asset exposure. You do this for two distinct reasons. First, as a firm, you have some level of risk aversion (likely less than an individual but your utility for money is still concave). There are many constructions for the shape of this utility function (e.g. CARA, CRRA, more generally HARA, etc.). Second, as a passive liquidity provider in the market, you are subject to adverse selection risk. Active liquidity takers could know something you don’t or just be smarter than you. It’s basically the problem of selling free options into the market. Also, even at a mechanical level, a market order that hits your bid ticks the price down in a mark-to-market way while a market order lifting your offer ticks the mark-to-market price up. At the exact instant of any trade, you are always on the wrong side. Beyond that, a market maker’s quotes create passive market impact. In other words, the act of posting an order into the book has at least a slight effect of moving the market away from you.

utility function of a risk-averse entity
The market takers’ perspectives are represented by the order flow. The volume-weighted frequency of order arrival as a function of depth from the top of the book should have a few key properties. The function should be 1) decreasing, 2) convex (the intuition here is difficult to explain but this is unambiguously the case empirically), 3) asymptotically approaching 0 as depth becomes infinite. Some formulations require that this intensity functionto be continuously twice differentiable for tractability which is a fine and reasonable assumption but ultimately unnecessary as well. Also, there are different formulations for how to calculate “depth or distance from top of the book”. You can generally use either some “fair mid price” or the best bid and best offer for each respective side. There are different tradeoffs between the two approaches which we won’t get into here. And beyond that, there is still a rabbit hole to go down on what a “fair mid price” should be. To add some color here, the mid price equidistant between the best bid and best offer is susceptible to noisiness when dust orders are posted and canceled. Also, given two cases with the same book shape, the last print being at the best bid would suggest a lower fair price than the last print being at the best offer. And there is another question of whether the history of the prints matter and if so should we look at it with respect to clock time or volume time? So where is the optimal limit order placement for a market maker given the characteristics of the flow in the market? If you post tight quotes near the top of the book, you will get filled often but make very little each time. If you post deep quotes, you will get filled less often but make “more” each time you are. This is effectively a convex optimization problem with a unique global maximum. Another consideration is order flow arrival across time which looks a bit like a Poisson process. Some suggest that it is closer to a Hawkes process. Moreover, bid-ask bounce, which a market maker tries to capture, is the shortest-term version of mean-reversion. Since this ultra short-term mean-reversion is scaled by local volatility, it makes sense for market makers to widen their quotes when vol is high and tighten their quotes when vol is low.
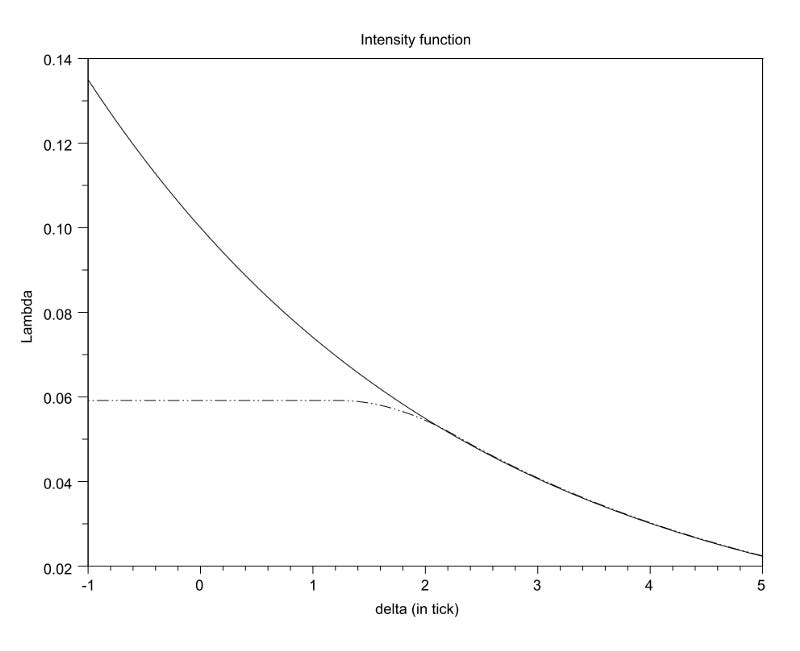
order arrival intensity with respect to depth

The other market makers’ perspectives are represented by the book. The book reveals some private information of other market makers. More offers than bids near the top of the book suggest other makers are more willing to sell than to buy an asset. It’s possible that these makers already have large positive imbalances in inventory or they simply believe that the price is more likely to go down than up in the short-term. In either case, you, as a market maker, can adjust your quotes based on the skew of the book. Moreover, when market makers compete with each other, if the tick size is small, you often see this “penny jumping” behavior. Market makers compete for fill priority by jumping each other and laddering up on the book until some capitulation point is reached and there is a sole “winner” for fill priority. After a winner has been determined, the runner-up often drops back down to one tick in front of of the next best bid or offer. If you lost fill priority, you might as well get second fill priority and pay only just enough for it. This causes a regress whereby the winner now drops back to one tick in front of the runner up and the laddering game restarts. You can see this laddering game in real crypto market data.

laddering game on the bid side
Finally, long-term directional signals can be overlaid on market making algos where the goal of the market making algo is no longer to keep inventory flat or constant but with some long-term target in mind and the corresponding skew to make it happen.
Speed
There are two main reasons speed matters. First, you are able to hit orders resting in the order book before they are canceled. Second, you are able to cancel orders resting in the order book before they are hit. In other words, you want to pick off stale orders and you want to avoid getting your orders picked off. Arbitrage algos (active) and execution algos (active) care more about the former while market making algos (passive) care more about the latter.
Generally the strategies that benefit the most from speed are the most basic. Any complex logic will necessarily slow down the roundtrip time. These types of algo strategies are the F1 cars of the trading world. Data validation, safety checks, instrumentation, orchestration, etc. might all be stripped away in favor of speed. Skip the OMS, EMS, and PMS (Portfolio Management System), and directly connect the computation logic on your GPUs to a colocated exchange’s binary API. A fast and dangerous game.
Another class of speed-sensitive strategies, relativistic statistical arbitrage strategies, servers to be physically positioned between multiple exchanges rather than colocated with an single exchange. While they will not be the fastest to data from any individual exchange, they will get and can act on correlation and cointegration data before any other strategy.

optimal intermediate trading node locations for the largest securities exchanges in the world
In the speed game, winner takes most. In the simplest example, if an arbitrage opportunity exists, whoever can get to it first will claim the profit. Second place gets crumbs and third place gets nothing. The payoffs are likely power law distributed.
The speed game is also a race to the bottom. Once everyone upgrades from fiber optics to microwave/laser networks, everyone is back on an even playing field and any initial advantage is commoditized away.
Tick Size, Fill Priority and Queue Position
Most matching engines obey price-time priority (pro-rata matching is a less common alternative but we don’t consider these for now). Limit orders at better prices get filled before limit orders at worse prices. For limit orders at the same price, the orders posted earlier get filled before orders posted later.
Binance discretizes their order books down to a maximum of 8 decimal places. If a symbol has a price of .000001, a tick of .00000001 is 1% of the price. If a symbol has a price of .0001, a tick of .00000001 is 1 bps of the price. This is a huge difference. In the former case, jumping ahead of a large order costs a full point so time priority matters more while in the latter case, it is 100x cheaper so price priority matters more. In other words, if you have to pay up a full 1% to get fill priority, it may not be worth it because your are paying up a relatively large amount while increasing your probability of getting filled by a relatively small amount and it’s probably better just to wait in line but if you only have to pay up 1 bps to get fill priority, you might as well do that because you decrease your edge by a relatively small amount while increasing your probability of getting filled by a relatively large amount. Smaller ticks favor price priority and larger ticks favor time priority.
This naturally leads to the next question: What is the value of your queue position?

fill probability as a function of queue position
Order Book Deltas
There are only two ways for a price level in the order book to decrement in quantity: either a trade crossed or a resting limit order was canceled. If a decrement was caused by a trade crossing, then all other price levels better than that would also cross and thus decrement. We can line up the ticker tape with tick-by-tick order opens and cancels and label each decrement as either a trade or a cancel. Intuitively, a trade means that two parties agreed to transact at a certain price while a cancel means that one party decided that it was no longer willing to buy or sell an asset at a certain price. Thus, at face value, we might say that a cancel at the best bid is a stronger signal that the market will move down in the short-term than a trade hitting that bid.
On the other hand, there is only one way for a price level in the order book to increment in quantity: a resting limit order gets posted.
Both increments and decrements in the order book reveal private information of market participants and thus provide short-term price signal.
Better Price Indices and Optimal Exchange Fees
Right now most price indices take trade data from multiple exchanges and aggregate them together to get a volume-weighted average price. Tradeblock indices, in particular, also add penalties to exchange weights for inactivity and for price deviations away from the rest of the pack. But is there something more we can do?
On GDAX, with a 0 bps maker fee and 30 bps taker fee, a printed trade at $4000/BTC hitting the offer side is effectively a seller selling at $4000/BTC and a buyer buying at $4012/BTC. The “fair price” of this trade should be closer to $4006/BTC rather than what was actually printed. On the other hand, because Bittrex’s fees of 25bps are symmetrically applied to both makers and takers, the fair price is the printed price. In other words, a print of $4000/BTC is effectively a buyer buying at $4010/BTC and a seller selling at $3990/BTC which averages out to the print itself.
So, from a price discovery standpoint, ticker tapes are not directly comparable between exchanges and instead should be netted of fees and standardized when constructing a price index. Of course, there are some complications here because of volume-based fee tiers, which may increase or decrease the maker-taker fee asymmetry as they are climbed so we can’t know for sure where buyers bought and where sellers sold. This also suggests two interesting corollaries.
First, price discovery is limited and in some ways schizophrenic on exchanges with strong maker-taker fee asymmetry. Assuming most accounts on GDAX are at the 0/30 bps maker-taker fee tier and noticing that GDAX often has 1 penny spreads on their BTCUSD book, each trade hitting printing at the bid is approximately “fair value” trading at 15bps below spot and each trade printing at the offer is approximately “fair value” trading at 15bps above spot. So the “fair price” during calm times is rapidly oscillating between those two points with no further granularity for price discovery between them.

Second, like tax incidence between producers and consumers, there is some equivalency between the maker and the taker on their fee incidence. If you charge makers relatively more, they widen out the book and pass on some of the fee incidence to takers. If you charge the takers relatively more, the makers tighten in the book and absorb some of the fee incidence from takers. The special edge case here is where you favor makers so much that the book squeezes to a single tick on the spread (like we often see on GDAX) and the book can’t get any tighter. Beyond this point, any extra fee incidence now falls on the exchange itself in terms of lost revenue. Outside of this special case, we can see that it doesn’t really matter to which side the fee is charged but rather it’s the sum of the maker and taker fee that matters. Ultimately, like the Laffer Curve in tax policy, exchanges face a revenue optimization problem in fee policy. We can see that the edge cases are the same as with tax policy. If an exchange charges no fees, they make no revenue. If the exchanges charge a 100% fee, there would be no trades and thus they would also make no revenue. With some additional thought, it’s clear that exchange revenue with respect to total fee level is a concave function with a unique maximum.

Proprietary Data
Every OTC desk has semi-unique labeled graph data of each of its counterparties addresses and the coinflows between them and known exchange addresses. Labeled data provides a good starting point for many kinds of machine learning algorithms.
Each miner has proprietary data on their marginal cost of minting a coin (in PoW). If they also have a sense of where they stand with respect to the rest of the miners in the world in terms of efficiency, they can derive unique insight on short-term supply gluts and shortages.
Black Boxes
Everyone knows black boxes are bad. It’s hard, if not impossible, to tell what’s going on and when something goes wrong, it’s profoundly difficult to diagnose why. Yet, many of the best hedge funds and prop shops eventually create black boxes. There’s a couple of very good reasons for this. First, people come and go at firms and badly documented legacy code will be difficult for newcomers to understand. Second, competition in the market means that any strategy a single mind can understand in it’s entirety will eventually lose to a strategy made in collaboration by experts and specialists in their own narrow field. Lastly, merging strategies is often better than running them separately. For example, suppose you had a long-term momentum strategy (S1) as well as a short-term mean-reversion strategy (S2). Surely, S1 could benefit from the short-term execution advantages of S2 and surely, S2 could benefit from the long-term drift predictions of S1. So naturally, we can combine them into a merged strategy which is more efficient than either of its constituents. Ultimately, strategies become black boxes, not because black boxes are desirable, but in spite of black boxes being undesirable.

Unraveling Confounding Factors
Suppose we had a model which predicted the frequency of Uber rides using a binary indicator of whether the ground was wet and it performed extremely well. Obviously, the ground being wet directly has nothing to do with Uber rides but, indirectly, rain causes the ground to be wet and rain also causes people to want to take Uber more. Even though our spurious model performs well, it is susceptible to tail-risk. If a water pipe bursts in a section of the city, causing the ground to be wet or there is natural flooding, we would wrongly predict that Uber rides should increase in frequency in that area.
In general, when A implies B (A=>B) and A implies C (A=>C), a model of B=>C might work but only incidentally. So it is imperative that predictive relationships conform with intuition and common sense. It is not enough to blindly data mine and find strong predictive signals, but we should aim to unravel any confounding factors from them before the signals aggregate into a black box, upon which, these factors will then be increasingly difficult to unravel.
Take a different example, say A=>B and B=>C. A model of A=>C will work but is inferior to a model of B=>C. First, A=>C leaves some money on the table because A may not be the only thing which causes (in the Granger causal sense) B; maybe A’ also causes B. Second, if the relationship A=>B breaks down, the A=>C model also breaks down but the B=>C model still works.
Feature Selection
Moving to multi-factor models, features should ideally be as orthogonal as possible to each other. For example, suppose we were investigating ice cream price as a function of sugar price and milk price. Perhaps a better model would be to use sugar price and season (spring, summer, fall, winter). The former model features are linked by inflation, are both of the category “food primitives/inputs” and “consumables”, and are both from the supply side of ice cream production while the latter model has 2 features which are much more orthogonal (one from the supply side and one from the demand side). Obviously using the 3 features of sugar price, milk price, and season would make a more accurate model but as the dimensionality of the model increases, calibrations will take at least super-linearly longer if not exponentially longer. By the time you have 20 features, it becomes intractable to run certain optimization methods like gradient descent so feature selection is key. We should drop correlated features in favor of more orthogonal features.
Epistemology
Both empiricism and deductive reasoning are valuable in the context of designing quantitative models.
One flaw of a purely empirical approach is that we cannot run controlled experiments in the markets. We cannot fix a point in time and try two different actions to see which performed better. In other words, there are no true counterfactuals in the soft/social sciences, unlike in the hard sciences. In trading, in particular, we are also unable to measure precisely the effect of our own actions on the market. In other words, during a historical time when we were not actively trading, we cannot know how the order book and flow would have behaved had we been actively trading and during a historical time when we were actively trading, we cannot know how the order book and flow would have behaved had we not been in the market. Another flaw of empiricism is that for any given historic pattern, there are an infinite number of models which would conform to the pattern but each could make an entirely different prediction of the future (i.e. a version of the black swan problem). Hume, Wittgenstein, Kripke, Quine, Popper, and Taleb all have many critiques and defenses of logical empiricism and the problem of induction that expounds further on these ideas.
One issue with pure deductive reasoning is that we as humans are error-prone. Any mistake of logic along a chain of deduction would immediately void the result. Furthermore, soundness of an conclusion requires not just that each logical step along the way is valid but that the premises we assume are true themselves and in accordance with reality. Since models must be tractable to be useful, they are often simplifications of the world and make assumptions which do not hold against reality.
Let’s look at an example. Suppose you were looking to run a Monte Carlo simulation for the trajectory of an asset price. If you take historic data on the asset returns and sample from them directly for your simulation paths, you run into the problem of 1) the data is sparse in the tails which represent extreme events and 2) you have some noisiness in the data away from some unknown true return probability distribution. Now, let’s say, instead of that, you fit the historic data to a normal distribution and then sample from it for your simulation paths. Now you run into a problem where returns are not actually normally distributed in reality (i.e. it’s leptokurtic; fat tails). So instead of all of that, you now fit historic returns to a Cauchy distribution or Levy distribution or even more generally to a Levy alpha-stable distribution. Now at this point, the model is getting more complex and you accidentally write a bug in the code. After a few days of toil, you figure out the problem and fix it. The code gets pushed to production and you have a working model… for about 2 years. 2 years later, it turns out that 5th moments matter and your Levy alpha-stable distribution does not capture this feature of reality. That’s basically how the game goes.

Lastly, here’s two heuristics I generally use: 1) When in doubt, default to common sense. 2) All else equal, simplicity and parsimony are better than complexity and bloat.
Real World Frictions
Having a theoretically profitable algo is one thing but dealing with the frictions of reality are another.
Suppose you send a request to an exchange to post an order and normally you get a callback confirming that the order was posted or that there was an error and the order failed to be posted. Say one day, you don’t get a callback on your post request. Do you consider this Schrodinger order posted or failed? You are susceptible to both type 1 (false positive) and type 2 (false negative) errors by misclassifying the order. Is one error type less costly than the other?
Suppose you are running an arbitrage strategy between two different exchanges. What do you do if one exchange’s API goes down in the middle of doing a pair of trades on both exchanges. One could have gone through but the other may have failed. Now you have unwanted inventory exposure. What’s the best way to handle this?
How do you handle post and cancel delays when an exchange is getting DDoS’d or the matching engine is stressed under load?
What about when exchanges make undocumented, unannounced changes to their APIs?
Suppose an exchange does balance updates for its customer balances in parallel to their matching engine executing trades so balances queried on the same millisecond or microsecond as a trade printing could report conflicting balance states to the client where it looks like a trade executed but balances have not yet changed. How can you design your own systems to synchronize to a consistent state of the world even if the exchange reports conflicting states to you?
Suppose the fees on an exchange are too high for you to place your limit orders at the model-derived optimal price. Or worse, some of your competitors were grandfathered into sweetheart deals with an exchange on fees. How would that change your behavior?
How do you handle fiat rebalancing if your bank doesn’t operate over the weekend but crypto trading is 24/7?
Arguably, an asset on one exchange is not perfectly fungible with the same asset on another exchange. First, each exchange’s counterparty risk is different, meaning the assets effectively bleed off differing negative interest rates. Second, because most exchanges have deposit/withdrawal limits, running into your limits means you can no longer physically rebalance assets between exchanges for some period of time.
In your accounting systems, how do you handle forks, airdrops, dust attacks, and other situations which you cannot opt out of?
Here’s a few heuristics that we generally follow. 1) Anything that can go wrong, will go wrong, even things you can’t currently currently think of, so build things to fail gracefully. 2) You and all third parties you connect with, like exchanges, will make mistakes. 3) Unlike consumer tech, don’t break things and iterate fast; rather, if you lose too much money, you won’t have a second chance. 4) Create system and data backups everywhere possible and create redundancies in your operational processes to account for human error. 5) Don’t use floating point types as precision loss could be very punishing for symbols with prices that are very small (e.g. KINBTC). 6) Reserve enough API calls from the API rate limit to burst cancel all open orders at all times.
Final Thoughts
Trading is one of the only jobs in the world where the direct goal is to turn capital into more capital. Couple that with Wild West nature of crypto and you get a cesspool of get-rich-quick types. Everyone wants the easy answers but no one wants to learn the craft. People want talking heads on TV to tell them about price targets, when to buy and when to sell. They want to buy that online trading course for $99.99 or that TA-based algo strategy for $19.99 per month. But no one would actually sell you a magic box that prints money; they would keep it for themselves. There are no magic formulas for generating PnL. The markets continuously evolve and the game only gets harder over time. The only way to stay ahead of the game is to hire the best talent, who can adapt and continuously outdo themselves.
The market is a giant poker table with millions of players sitting down, each of whom believes he or she can outplay his or her neighbor. And there is already a bit of self-selection for the people who sit at this table. Winning means playing better than a little bit more than half the capital at the table which, in turn, means you need to be better than 90% of the players since capital accrues to winners in power law fashion.
Culturally, the trading game is different from VC investing. In Silicon Valley, it pays to be what Peter Thiel calls a definite optimist. You need to believe that new technology will change the world and that you can and will chart a course to make that happen. Over in Chicago where the prop shops are, the culture is much different. There, it pays to be a highly adversarial thinker. Everyone wants to win as badly as you do and every time you make a trade, you have that nagging thought in the back of your mind that maybe the person on the other side knows something you don’t. A startup in the Valley must first battle the indifference of the world before they face any real competition in the market. A trading shop, on the other hand, while not having customers to deal with, cannot avoid competition even from the very beginning. The very best shops, shroud themselves in secrecy. Crypto trading is the intersection of those two worlds and there are no clear winners in this nascent space. We, at Galois Capital, aspire toward that goal.
If you are interested in the problems we are tackling and are willing to get down to the nitty gritty of algo-trading, check out our careers page at galois.capital/careers and give us a ping at contact@galois.capital.
Author: Kevin Zhou | galois.capital